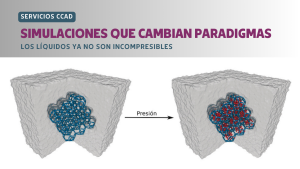
El sistema de archivos de Serafín fue actualizado en hardware y en software. Más capacidad de SSD para metadatos, nuevos procesadores, nueva placa de comunicaciones y actualizaciones de software. Te contamos de que se trata. ¿Para que tener mucho cómputo si el almacenamiento tiene mucha latencia o poco ancho de banda? ¿Y si te decimos …