
Entradas del autor
Jun 25 2024
Resultados del Reempadronamiento en CCAD
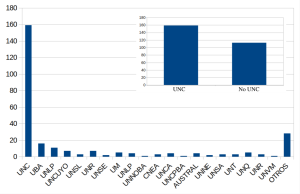
Inspirados por un procedimiento de reempadronamiento del NLHPC, en 2024 pedimos a todas/os las usuarias/os que indicaran que son usuarias/os activos. También preguntamos sobre sus trabajos científicos realizados, aportes al CCAD para su funcionamiento y qué proyectan para este año. Desde hace ya varios años que tenemos una activa y muy buena relación con nuestras …
May 28 2024
Circulando RAM a Bariloche

Hace poco recibimos partes de COSMA6, una supercomputadora del Reino Unido. Pasamos un décimo de estas memorias al Centro Átómico Bariloche para que puedan incrementar la cantidad de RAM de varios servidores de cómputo. Apenas recibimos la donación de Durham, vimos que teníamos más módulos de RAM de los que necesitabamos de manera inmediata. Para …
May 18 2024
Modelos de Lenguaje GRANDES en GPUs chicas
Como estudiantes de doctorado en Aprendizaje Automático en FaMAF-UNC, disponemos de capacidades de cómputo a través del CCAD. Aunque éstas están a la vanguardia a nivel nacional, aun así resultan insuficientes para entrenar modelos grandes de lenguaje. En este artículo técnico describimos experimentos para «pegar» dos NVIDIA A30 de 24 GiB y así poder entrenar …
Abr 14 2024
La Fundación Vía Libre nos ayuda con Hardware

Todo suma y la Fundación Vía Libre nos da una mano con hardware variopinto que necesitamos. La diaria de hacer HPC no es comprar 15 chasis con 60 nodos, es otra cosa, un poco más precisa, más pequeña, pero fundamental para que todas las piezas encajen. ¿Qué hacemos con un riser PCIe, una NIC InfiniBand, …
Abr 05 2024
CCAD le da una segunda vida a COSMA6

La Universidad de Durham donó partes de COSMA6 al CCAD que serán usadas para mejorar las capacidades de red de alta velocidad y de memoria de nuestros clusters más viejos. Desde hace años que existe una relación muy fluida entre Durham University y la UNC a través de las y los investigadores del IATE-CONICET en …
Feb 07 2024
Todos los racks del CCAD con energía

La empresa PROIMA energizó 6 racks con 150 KVA, duplicando así la capacidad de alojar equipamiento de cómputo de alto desempeño. El costo de la obra aportados por el Rectorado de la UNC fue cercano a 40.000 dólares estadounidenses. En marzo de 2022 en una fructífera reunión con el entonces Rector de la UNC, el …
Feb 04 2024
Todo Serafín con 256 GiB de RAM

Supermicro, el proveedor de Serafín, terminó de realizar el cambio de memorias. Ahora los 60 nodos de cómputo tienen 256 GiB de RAM y el nodo cabecera 128 GiB, duplicando la memoria de la configuración original. En agosto de 2023 llegó un lote de memoria de recambio para reemplazar módulos DDR4-3200 de 8 GiB que …
Dic 20 2023
Los tres grandes problemas del HPC son dos, el metadata server

El sistema de archivos de Serafín fue actualizado en hardware y en software. Más capacidad de SSD para metadatos, nuevos procesadores, nueva placa de comunicaciones y actualizaciones de software. Te contamos de que se trata. ¿Para que tener mucho cómputo si el almacenamiento tiene mucha latencia o poco ancho de banda? ¿Y si te decimos …
Dic 18 2023
Instalamos 18 GPUs en Mendieta Fase 2

MendietaF2, el cluster de GPUs para dinámica molecular y aprendizaje automático fue expandido con 18 GPUs y llegó a la capacidad máxima planificada. Los 22 nodos de Mendieta ya están completamente llenos de NVIDIA A30. Con fondos del Rectorado de la UNC, empezó un proceso de compra de abril a noviembre donde se invirtieron 57708 …
Nov 15 2023
Área Económico-Financiera visita sus Compras

Las trabajadoras y trabajadores del Área Económico-Financiera de la PSI que prestan servicios al CCAD, visitaron el UNC Data Center para conocer todos lo bienes que posibilitaron comprar. Laura Grassetti, Ana Laura Calderón y Gonzalo Jaimez, están detrás de la operación diaria del CCAD. Ellos gestionan los fondos y realizan todas y cada una de …
HITOS


