
Como estudiantes de doctorado en Aprendizaje Automático en FaMAF-UNC, disponemos de capacidades de cómputo a través del CCAD. Aunque éstas están a la vanguardia a nivel nacional, aun así resultan insuficientes para entrenar modelos grandes de lenguaje. En este artículo técnico describimos experimentos para «pegar» dos NVIDIA A30 de 24 GiB y así poder entrenar un modelo que no entraba en una sola GPU con buenos resultados de desempeño.
LLaVA acrónimo de «Large Language and Vision Assistant», es un modelo multimodal de última generación, open-source y de gran tamaño, diseñado para ser un asistente visual avanzado capaz de comprender tanto imágenes como instrucciones en lenguaje natural, y poder realizar una amplia variedad de tareas en el mundo real. A pesar de haber sido entrenado con un conjunto de datos relativamente pequeño, LLaVA demostró habilidades excepcionales alcanzando comportamientos y rendimientos comparables a los entregados por conocidos modelos multimodales propietarios como GPT-4 y Gemini de las compañias OpenAI y Google, respectivamente. Además, demostró altas capacidades para razonar y responder a consultas que se alinean con la intención humana, superando a otros modelos open-source como BLIP-2 y OpenFlamingo (ver detalles aquí).

En contraste con enfoques anteriores, donde los modelos de visión y lenguaje operaban de forma independiente utilizando el lenguaje solo para describir el contenido de las imágenes, LLaVA se destaca por su capacidad para fusionar la potencia de los grandes modelos de lenguaje (LLM, Large Language Models), con avanzados codificadores de visión, creando de esta manera un asistente muy versátil capaz de comprender y actuar sobre instrucciones que combinan ambas modalidades.
La arquitectura de LLaVA se basa inicialmente en el modelo de lenguaje LLaMA, y en sus versiones más recientes ha incorporado otros como Vicuna y Mistral. Para el procesamiento del contenido visual, LLaVA aprovecha el codificador visual preentrenado CLIP de OpenAI.
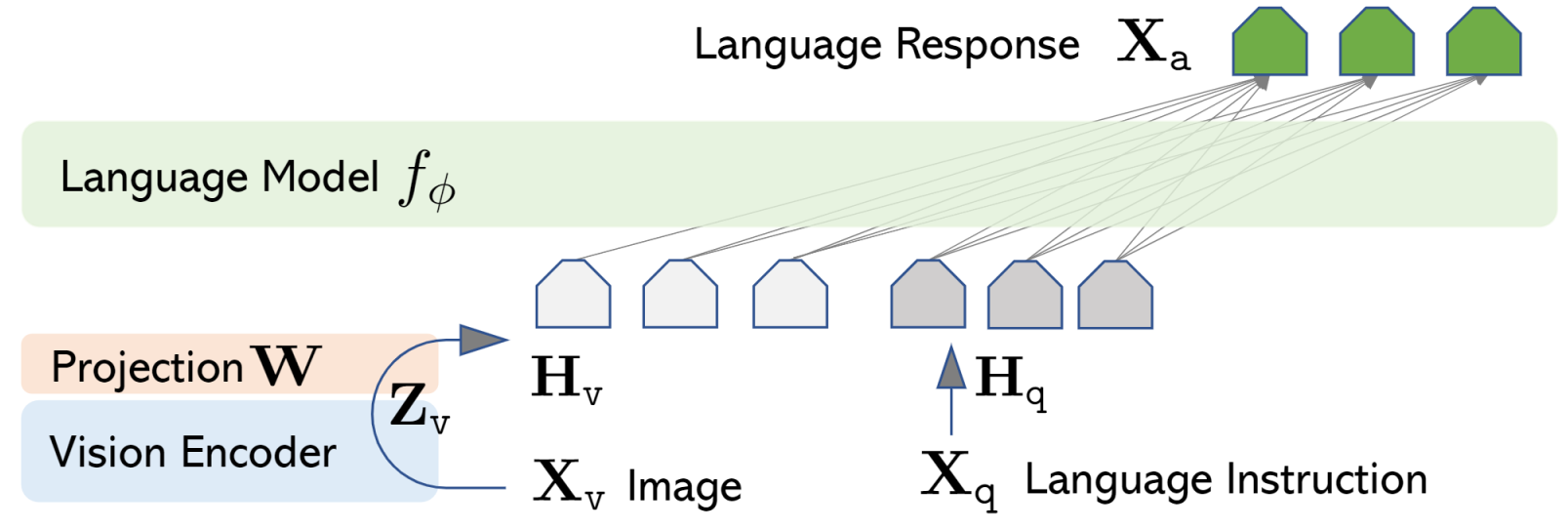
El entrenamiento de LLaVA es llevado a cabo utilizando la estrategia de «Visual Instruction Tuning». Este proceso implica adaptar el modelo para comprender instrucciones multimodales basadas en señales visuales, permitiendo relacionar instrucciones lingüísticas con contenido visual y dotándolo de capacidades para abordar una amplia gama de aplicaciones del mundo real.
¿Como se realizaron los experimentos?
Todas las pruebas se realizaron utilizando dos GPUs NVIDIA A30, cada una con 24 GB de VRAM HBM2. Estas pruebas se llevaron a cabo empleando la tarea de VQA sobre un subconjunto de datos compuesto por un total de 6081 pares de preguntas e imágenes extraídas del conjunto de datos VizWiz-VQA, especialmente diseñado por y para personas con discapacidades visuales. VQA, o «Visual Question Answering» (Respuestas a Preguntas Visuales), es un campo de investigación en inteligencia artificial que se enfoca en desarrollar sistemas capaces de responder preguntas sobre imágenes.
Durante los experimentos, se emplearon dos versiones diferentes del modelo LLaVA 1.5: una versión más pequeña con 7 mil millones de parámetros (7B) y una versión más grande con un total de 13 mil millones de parámetros (13B), ambas cuantizadas a 16 bits.
Para evaluar el rendimiento de los modelos, se utilizó la métrica de inferencias por segundo (inf/s), que indica la cantidad de inferencias que el modelo puedo realizar en un segundo. Esta métrica se calculó promediando los tiempos de inferencia totales obtenidos a lo largo de tres iteraciones de predicciones de respuestas para cada uno de los 6081 pares de preguntas e imágenes del conjunto de datos seleccionado.
Con el fin de evaluar la velocidad de comunicación entre las placas de video en un mismo servidor (a través de los buses PCI express), se llevaron a cabo los siguientes experimentos. En primer lugar, se ejecutó el modelo completo en una sola GPU para establecer una referencia y medir su rendimiento correspondiente. Posteriormente, el modelo se dividió en dos partes y cada una se alojó en una GPU diferente, lo que permitió evaluar cómo influye la comunicación entre las GPU en el rendimiento total obtenido.
Este enfoque se aplicó tanto a la versión del modelo de 7B parámetros como a la de 13B. En ambos casos, fue necesario reducir la cantidad de bits utilizados por los pesos del modelo a la mitad, pasando de precisión completa (32 bits) a media precisión (16 bits). Para la primera versión, esta reducción permitió tanto la carga completa del modelo en la VRAM de una sola GPU como su división entre ambas GPUs. Sin embargo, para la segunda versión, debido a su tamaño más grande, solo fue posible alojarla utilizando la capacidad total brindada por las VRAM de ambas GPUs.
Sistemas bajo Prueba
Tenemos dos sistemas uno es uno de los nodos de nuestro cluster MendietaF2 y el otro es un nodo del Proyecto NodoAICba gestionado por el MinCyT-Córdoba (2021), donde se compraron 3 servidores para aprendizaje automático iguales, uno para San Francisco, otro para Villa María y el restante para Río Cuarto. La diferencia principal es que NodoAI tiene una CPU más potente y el doble de ancho de banda de comunicación a las GPUs a través de PCIe 4.0.
Queríamos conocer cuanto perdermos estando en un procesador de Q3’13 con PCIe 3.0 frente a una alternativa más moderna.
MedietaF2
Hardware: Supermicro 1027GR-TSF, placa madre X9DRG-HF, CPU dual Intel Xeon E5-2680v2 (10 cores Ivy Bridge EP con AVX256, PCIe 3.0), RAM 64 GiB DDR3@1600 MT/s, GPU dual NVIDIA A30 (GA100GL, 28 SM Ampere, 24 GiB HBM2).
Software: Rocky Linux 8.8, NVIDIA Driver 535.54.03, CUDA 12.2.
NodoAI
Hardware: Gigabyte G242-Z11 (rev. A00), CPU AMD EPYC 7453, (28 cores Milan, AVX2, PCIe 4.0), RAM 256 GiB DDR4@3200 MT/s , GPU dual NVIDIA A30 (GA100GL, 28 SM Ampere, 24 GiB HBM2).
Software: Rocky Linux 8.6, NVIDIA Driver 525.85.12, CUDA 12.0.
Experimentos
MendietaF2
LLaVA-1.5 7B (Quantization: 16bits – VRAM: ~16GiB)
Split Across 1 GPU
100%|██████████| 6081/6081 [36:33<00:00, 2.77it/s] 100%|██████████| 6081/6081 [31:33<00:00, 3.21it/s] 100%|██████████| 6081/6081 [31:32<00:00, 3.21it/s]
N: 6081
Avg Inference time: 1992.96 sec.
Rate: 3.05 inference/sec.
Split Across 2 GPUs
100%|██████████| 6081/6081 [35:49<00:00, 2.83it/s] 100%|██████████| 6081/6081 [36:36<00:00, 2.77it/s] 100%|██████████| 6081/6081 [36:45<00:00, 2.76it/s]
N: 6081
Avg Inference time: 2183.89 sec.
Rate: 2.78 inferences/sec.
PCIe logs
# gpu pwr gtemp mtemp sm mem enc dec jpg ofa mclk pclk rxpci txpci
# Idx W C C % % % % % % MHz MHz MB/s MB/s
0 50 30 41 33 27 0 0 0 0 1215 1440 77 4
1 70 32 49 34 31 0 0 0 0 1215 1440 0 1
0 49 30 41 0 0 0 0 0 0 1215 1440 22 7
1 116 34 49 100 17 0 0 0 0 1215 1425 36 9
0 47 30 40 0 0 0 0 0 0 1215 1440 9 4
1 168 37 49 100 17 0 0 0 0 1215 1365 20 7
0 47 32 41 100 17 0 0 0 0 1215 1440 9 3
1 165 36 49 100 17 0 0 0 0 1215 1380 21 7
0 164 36 41 90 15 0 0 0 0 1215 1365 11 2
1 47 31 49 0 0 0 0 0 0 1215 1440 9 3
0 166 36 41 78 13 0 0 0 0 1215 1365 6 3
1 47 31 49 0 0 0 0 0 0 1215 1440 9 3
0 173 33 41 13 9 0 0 0 0 1215 1380 7 3
1 47 32 49 40 15 0 0 0 0 1215 1440 9 3
0 49 30 40 13 9 0 0 0 0 1215 1440 15 4
1 48 32 49 63 20 0 0 0 0 1215 1440 2 3
0 68 30 41 11 7 0 0 0 0 1215 1440 76 3
1 89 34 49 78 21 0 0 0 0 1215 1440 0 0
0 68 30 40 0 0 0 0 0 0 1215 1440 8 2
1 79 35 50 100 17 0 0 0 0 1215 1425 0 0
0 49 30 40 0 0 0 0 0 0 1215 1440 9 277
1 165 37 49 100 17 0 0 0 0 1215 1425 18 0
0 49 30 41 0 0 0 0 0 0 1215 1440 9 3
1 166 38 49 100 17 0 0 0 0 1215 1365 0 4
0 48 31 41 0 0 0 0 0 0 1215 1440 9 4
1 165 37 49 100 17 0 0 0 0 1215 1365 21 7
0 47 32 41 100 17 0 0 0 0 1215 1440 9 4
1 163 36 49 12 2 0 0 0 0 1215 1365 19 7
0 49 33 41 88 15 0 0 0 0 1215 1425 9 4
1 192 36 49 31 5 0 0 0 0 1215 1365 19 7
0 168 36 41 23 5 0 0 0 0 1215 1365 9 3
1 48 32 49 0 0 0 0 0 0 1215 1440 9 3
0 50 30 41 33 27 0 0 0 0 1215 1440 15 4
1 67 33 49 34 31 0 0 0 0 1215 1440 3 3
0 104 31 41 0 0 0 0 0 0 1215 1440 0 0
1 56 34 50 100 17 0 0 0 0 1215 1440 0 0
0 49 30 41 0 0 0 0 0 0 1215 1440 4284 7
1 165 36 50 100 17 0 0 0 0 1215 1425 26 0
0 47 30 41 0 0 0 0 0 0 1215 1410 9 3
1 163 38 50 100 17 0 0 0 0 1215 1365 2 1
0 48 31 41 0 0 0 0 0 0 1215 1440 9 3
1 160 38 50 100 17 0 0 0 0 1215 1365 19 7
LLaVA-1.5 13B (Quantization: 16bits; VRAM: ~32GiB
Split Across 2 GPUs
100%|██████████| 6081/6081 [49:55<00:00, 2.03it/s] 100%|██████████| 6081/6081 [49:39<00:00, 2.04it/s] 100%|██████████| 6081/6081 [50:09<00:00, 2.02it/s]
N: 6081
Avg Inference time: 2994.59 sec.
Rate: 2.03 inference/sec.
PCIe logs
# gpu pwr gtemp mtemp sm mem enc dec jpg ofa mclk pclk rxpci txpci
# Idx W C C % % % % % % MHz MHz MB/s MB/s
0 52 30 40 55 19 0 0 0 0 1215 1440 31 1
1 92 31 49 63 24 0 0 0 0 1215 1440 14 0
0 45 30 40 41 19 0 0 0 0 1215 1365 2 1
1 91 32 49 37 24 0 0 0 0 1215 1440 0 0
0 59 31 40 54 24 0 0 0 0 1215 1410 11 131
1 236 34 49 4 2 0 0 0 0 1215 1215 0 2
0 99 31 41 27 12 0 0 0 0 1215 1380 10 6
1 190 34 49 46 22 0 0 0 0 1215 1215 1 0
0 56 29 40 18 10 0 0 0 0 1215 1440 0 0
1 92 31 49 25 21 0 0 0 0 1215 1440 0 0
0 51 29 40 17 11 0 0 0 0 1215 1440 24 1
1 94 31 49 29 24 0 0 0 0 1215 1440 12 0
0 170 32 41 53 24 0 0 0 0 1215 1320 4047 23
1 173 33 49 11 10 0 0 0 0 1215 1365 42 8
0 97 30 41 47 21 0 0 0 0 1215 1440 2 8
1 44 32 49 57 26 0 0 0 0 1215 1425 24 9
0 48 29 40 24 17 0 0 0 0 1215 1440 0 0
1 58 31 48 65 33 0 0 0 0 1215 1440 0 0
0 93 31 40 24 17 0 0 0 0 1215 1335 28 7
1 48 31 48 11 10 0 0 0 0 1215 1440 375 13
0 101 30 40 50 23 0 0 0 0 1215 1440 2 8
1 44 32 49 12 6 0 0 0 0 1215 1425 26 8
0 49 29 40 17 11 0 0 0 0 1215 1440 29 7
1 48 31 48 23 19 0 0 0 0 1215 1440 11 3
0 243 33 41 10 8 0 0 0 0 1215 1215 25 371
1 48 32 49 0 0 0 0 0 0 1215 1230 10 0
0 47 30 40 53 24 0 0 0 0 1215 1425 45 7
1 165 33 49 0 0 0 0 0 0 1215 1395 42 10
0 50 30 40 54 24 0 0 0 0 1215 1440 0 0
1 94 32 49 62 30 0 0 0 0 1215 1440 0 0
0 63 32 41 29 13 0 0 0 0 1215 1380 10 5
1 168 35 49 43 21 0 0 0 0 1215 1200 6 0
0 66 29 40 25 21 0 0 0 0 1215 1200 27 7
1 45 31 48 16 14 0 0 0 0 1215 1395 368 13
0 39 30 40 54 24 0 0 0 0 1215 1425 31 1
1 90 33 49 57 26 0 0 0 0 1215 1425 10 0
NodoIA
LLaVA-1.5 7B (Quantization: 16bits – VRAM: ~16GiB)
Split Across 1 GPU
100%|██████████| 6081/6081 [22:46<00:00, 4.45it/s] 100%|██████████| 6081/6081 [22:44<00:00, 4.46it/s] 100%|██████████| 6081/6081 [22:40<00:00, 4.47it/s]
N: 6081
Avg Inference time: 1363.74 sec.
Rate: 4.46 inference/sec.
Split Across 2 GPUs
100%|██████████| 6081/6081 [24:07<00:00, 4.20it/s] 100%|██████████| 6081/6081 [24:00<00:00, 4.22it/s] 100%|██████████| 6081/6081 [24:03<00:00, 4.21it/s]
N: 6081
Avg Inference time: 1443.68 sec.
Rate: 4.21 inference/sec.
PCIe logs
# gpu pwr gtemp mtemp sm mem enc dec mclk pclk rxpci txpci
# Idx W C C % % % % MHz MHz MB/s MB/s
0 167 40 36 100 17 0 0 1215 1380 8 2
1 48 34 33 0 0 0 0 1215 1440 10 3
0 162 39 36 89 15 0 0 1215 1365 7 2
1 49 35 33 0 0 0 0 1215 1440 10 3
0 161 40 36 99 17 0 0 1215 1365 11 2
1 48 35 33 0 0 0 0 1215 1440 10 3
0 166 40 36 100 17 0 0 1215 1380 11 2
1 48 35 34 0 0 0 0 1215 1440 10 3
0 164 39 37 49 23 0 0 1215 1365 12 2
1 49 36 34 0 0 0 0 1215 1440 10 3
0 180 39 36 56 28 0 0 1215 1335 9 3
1 49 36 34 40 32 0 0 1215 1440 10 3
0 60 37 35 0 0 0 0 1215 1440 14 3
1 52 38 35 60 19 0 0 1215 1440 10 3
0 97 35 36 3 2 0 0 1215 1440 19 2
1 65 39 38 100 17 0 0 1215 1440 0 0
0 49 34 34 0 0 0 0 1215 1440 37 10
1 111 39 38 100 17 0 0 1215 1440 12 11
0 48 35 34 0 0 0 0 1215 1440 10 3
1 165 43 36 100 17 0 0 1215 1365 104 2
0 49 35 35 0 0 0 0 1215 1440 10 90
1 164 43 36 90 16 0 0 1215 1395 98 3
0 48 36 35 100 17 0 0 1215 1440 10 88
1 163 43 36 79 14 0 0 1215 1395 99 2
0 55 37 36 94 17 0 0 1215 1425 10 89
1 176 42 36 0 0 0 0 1215 1395 98 2
0 164 42 38 100 17 0 0 1215 1380 8 659
1 49 38 35 0 0 0 0 1215 1440 102 2
0 174 39 37 38 28 0 0 1215 1395 7 3
1 50 37 36 44 41 0 0 1215 1440 10 3
0 58 35 36 0 0 0 0 1215 1440 0 0
1 57 39 37 56 26 0 0 1215 1440 0 0
0 48 35 35 0 0 0 0 1215 1440 48 7
1 168 42 40 100 17 0 0 1215 1425 41 14
0 48 35 35 0 0 0 0 1215 1440 10 88
1 165 45 37 100 17 0 0 1215 1395 8 4108
0 48 36 35 0 0 0 0 1215 1440 10 3
1 167 45 37 100 17 0 0 1215 1395 10 2
0 49 36 36 3 1 0 0 1215 1440 11 89
1 170 44 37 100 17 0 0 1215 1395 98 3
0 49 37 36 28 5 0 0 1215 1440 10 88
1 171 44 37 50 9 0 0 1215 1395 94 2
0 48 38 36 100 18 0 0 1215 1440 10 3
1 166 43 37 67 12 0 0 1215 1395 8 3
LLaVA-1.5 13B (Quantization: 16bits; VRAM: ~32GiB
Split Across 2 GPUs
100%|██████████| 6081/6081 [37:50<00:00, 2.68it/s] 100%|██████████| 6081/6081 [37:55<00:00, 2.67it/s] 100%|██████████| 6081/6081 [37:54<00:00, 2.67it/s]
N: 6081
Avg Inference time: 2273.64 sec.
Rate: 2.67 inference/sec.
PCIe logs
# gpu pwr gtemp mtemp sm mem enc dec mclk pclk rxpci txpci
# Idx W C C % % % % MHz MHz MB/s MB/s
0 51 41 43 49 25 0 0 1215 1230 27 7
1 50 39 37 64 34 0 0 1215 1440 208 8
0 113 41 43 36 23 0 0 1215 1215 18 175
1 207 42 41 23 19 0 0 1215 1260 205 7
0 62 38 38 43 27 0 0 1215 1425 4559 10
1 68 41 43 20 17 0 0 1215 1395 0 0
0 69 41 43 21 17 0 0 1215 1230 27 7
1 50 39 38 47 30 0 0 1215 1440 565 8
0 100 38 42 50 41 0 0 1215 1440 92 7
1 93 40 44 46 39 0 0 1215 1440 0 0
0 244 41 44 48 30 0 0 1215 1215 10 175
1 209 43 42 23 19 0 0 1215 1230 204 7
0 189 39 39 14 9 0 0 1215 1365 10 176
1 164 43 43 44 25 0 0 1215 1245 16 17
0 204 41 42 54 32 0 0 1215 1365 10 133
1 209 44 43 22 19 0 0 1215 1230 108 1
0 46 38 40 46 22 0 0 1215 1425 92 6
1 118 41 44 7 4 0 0 1215 1425 0 0
0 48 39 44 44 21 0 0 1215 1440 19 0
1 102 41 42 60 31 0 0 1215 1425 0 0
0 99 39 41 55 25 0 0 1215 1440 33 12
1 87 41 44 42 21 0 0 1215 1425 81 13
0 170 40 40 56 30 0 0 1215 1380 11 179
1 183 44 43 19 13 0 0 1215 1230 2 17
Resúmen
inf/s = Número de inferencias realizadas por el modelo en un segundo.
LLaVA-1.5 7B
Quantization:
fp16; total VRAM used:~16GiB
| Model Split Across | MendietaF2 | NodoIA |
|---|---|---|
| 1 GPU | 3.051 inf/s | 4.459 inf/s |
| 2 GPUs | 2.784 inf/s | 4.212 inf/s |
LLaVA-1.5 13B
Quantization:
fp16; total VRAM used:~32GiB
| Model Split Across | MendietaF2 | NodoIA |
|---|---|---|
| 2 GPUs | 2.031 inf/s | 2.674 inf/s |
Logramos hacer funcionar de manera razonable en dos configuraciones de servidor con pares de GPU A30, se vió que para el modelo que realmente no entra en toda la VRAM de una GPU, la diferencia de rendimiento entre PCIe 3.0+IvyBride vs PCIe 4.0+Milan no resulta considerable.
Por Hernán Maina
Estudiante de Doctorado de FaMAF-UNC


