
Jerónimo Fotinós y su director Lucas Barberis, están trabajando sobre simulaciones de crecimiento de tumores cancerígenos in vitro. Dentro de su doctorado Jerónimo pasó el código de 2D a 3D y se encontró con que necesitaba una gran cantidad de cómputo. Carlos Bederián, CPA Principal del CCAD, aportó su experiencia y aceleró el código por 39 veces.
 Recientemente Carlos Bederián aportó mejoras al código Python de Jerónimo Fotinós, estudiante del Doctorado en Física de FaMAF-UNC, dirigido por Lucas Barberis. La aceleración de código que logró el CPA de CONICET fué brutal: logró mutiplicarlo por 39. Es por eso que entrevistamos a Jerónimo, para que nos cuente de qué se trató y qué habilita esta aceleración
Recientemente Carlos Bederián aportó mejoras al código Python de Jerónimo Fotinós, estudiante del Doctorado en Física de FaMAF-UNC, dirigido por Lucas Barberis. La aceleración de código que logró el CPA de CONICET fué brutal: logró mutiplicarlo por 39. Es por eso que entrevistamos a Jerónimo, para que nos cuente de qué se trató y qué habilita esta aceleración
Nicolás Wolovick: ¿Qué hace el código?
Jerónimo Fotinós: El programa simula crecimiento de tumores cancerígenos in vitro. En particular, modelamos computacionalmente ensayos de tumoresferas: un modelo biológico para el estudio del cáncer, enfocado en las características y respuesta a terapias de las Células Madre Cancerosas (CMC).
Concretamente, el programa simula la reproducción y proliferación de células en un ensayo de tumoresferas con dos especies celulares: células madre y células diferenciadas. El primer objetivo es obtener la distribución espacial de las primeras, contrastarla con datos experimentales y modelarlas matemáticamente.
 NW: ¿Por qué es importante?
NW: ¿Por qué es importante?
JF: El programa nos permite evaluar si existe un umbral para la capacidad de autoreplicación de las CMC, tal que, por encima de este valor, logren proliferar en la periferia del tumor. Esto puede relacionarse con una transición de percolación en el modelo como sugieren los resultados preliminares. Que una CMC -que suelen ser muchas menos que sus contrapartes diferenciadas- consiga o no ubicarse y mantenerse en la periferia del tumor, tiene fuertes implicancias en la resistencia a las quimio/radioterapias como así también en el entendimiento del fenómeno de metástasis.
NW: ¿Ya tienen publicaciones?
JF: Todavía no hay publicaciones al respecto, empecé a trabajar en esto en abril. Sí hay una publicación de Lucas al respecto, pero no es con este código (él usó un código en NetLogo) para el caso 2D que no es biológicamente relevante pero sirvió para organizar lo que hay que hacer. El código que optimizó Carlos es el que desarrollé yo, lo denominé tumorsphere_culture, permite extender el problema a 3D -como ocurre con las tumoresferas experimentales- y realizar cálculos que posibilitan describir diferentes posiblidades de la progresión tumoral.
NW: ¿Cómo llegaron a contactarse con Carlos? Me comentaron que les quedaban cortos los 2 días de tiempo límite en Serafín.
JF: Yo le consulté a Carlos sobre la posibilidad de correr durante más tiempo porque había escuchado que a veces en las vacaciones de invierno te dejaban, y él me habló del uso exclusivo a raíz de eso. Considerando que para realizar algunas aproximaciones matemáticas útiles, es necesario llegar a tener millones de células que representan unos 100 días de cultivo, y que el tiempo para calcuar un día crece exponencialmente, vamos a requerir a futuro más recursos. Además, esto es sólo la punta del témpano. Posteriormente el modelo deberá incluir otros tipos celulares, interacción específica con el medio, mecanismos internos de las células, entre otros, que van a aumentar drásticamente el tiempo de cálculo, incluso para sistemas relativamente pequeños.
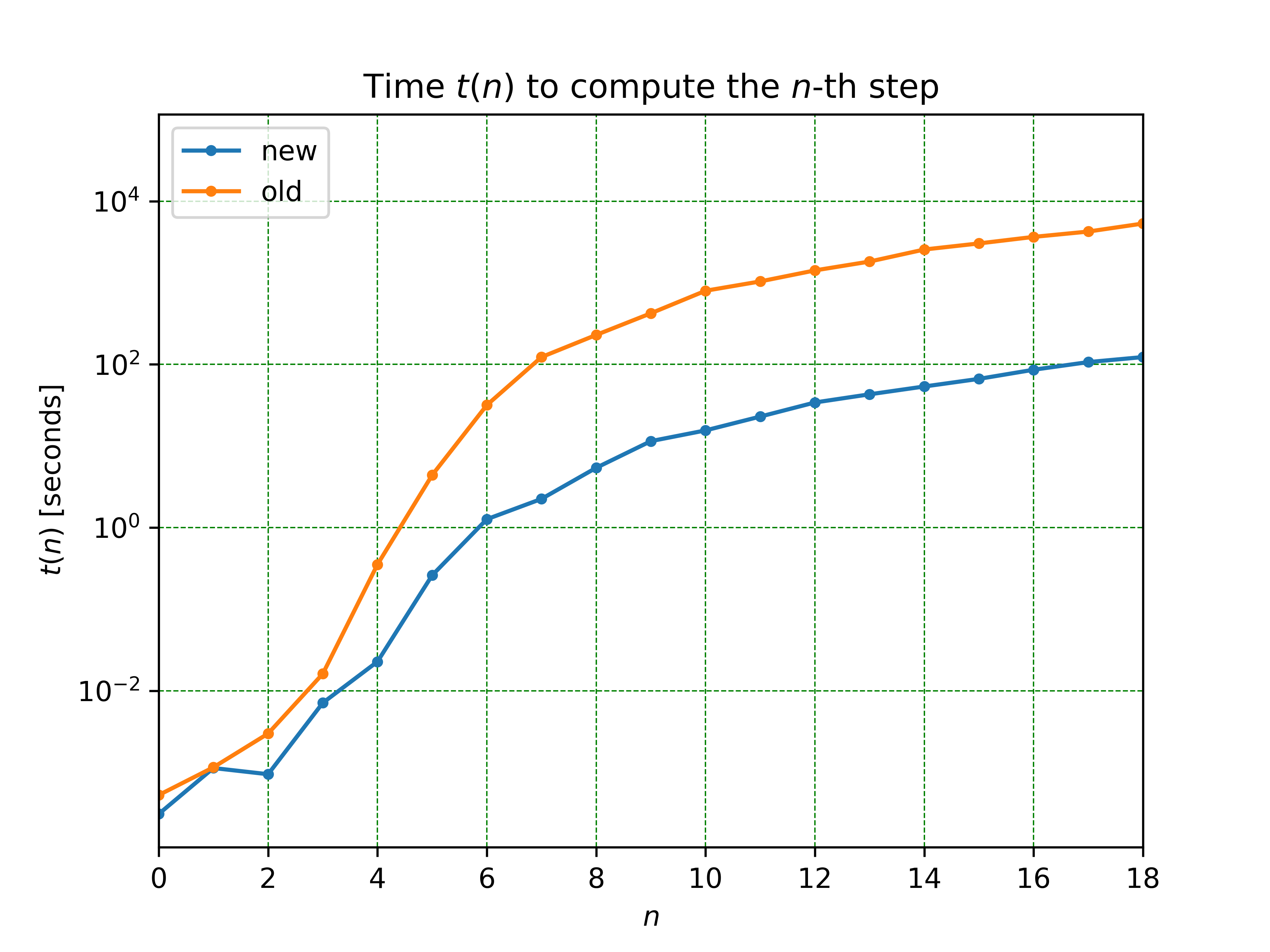 NW: ¿Qué podrán hacer con el 39x que logró Bederián?
NW: ¿Qué podrán hacer con el 39x que logró Bederián?
JF: Sin esa aceleración no era posible hacer corridas útiles en menos de dos días, así que antes que nada, la aceleración posibilitó la ejecución en los clusters. En segundo lugar, esta aceleración nos permite correr un número mayor de simulaciones con diferentes parámetros e incluir mayor cantidad de realizaciones de un mismo experimento para contar con valores estadísticos confiables. Esto último es central a la hora de medir los observables que requerimos para el modelado matemático.
NW: ¿Entendiste la lógica de los cambios que hizo Carlos? ¿Vas a poder aplicar estas estrategias para que tu código siga performante?
JF: Si, los entiendo y casi todos son cosas que incorporé desde el momento en que las vi en sus commits, porque era una cuestión de no saber que era más rápido hacer las cosas de ese modo. La única cosa de la que no estoy seguro es si las anotaciones de tipo (mediante typing) cambian la performance. Yo tenía entendido que no, pero quizás eso cambió ya. Pero para responder tu pregunta, sí, incluso en los cambios que estoy haciendo ahora, estoy pudiendo aplicar estas estrategias para que el código siga performante. En particular, el tema de almacenar vectores en una única matriz y que los objetos no guarden vectores, sino su índice en la matriz.
NW: ¿Qué desafíos quedan aún en el código?
JF: El desafío central que queda es que todavía requerimos una gran cantidad memoria. En el estado actual del código, no es posible aprovechar todos los cores de un nodo, porque la memoria del mismo se agota antes de terminar la simulación. En este momento estoy haciendo las modificaciones que creo necesarias para solucionar eso. Un segundo desafío sigue siendo la aceleración. Si bien la mejora respecto al original es enorme, todavía no permite correr 60 pasos, que representan 60 días experimentales, en 2 días. Este es el número mínimo de pasos que necesitamos simular de acuerdo a nuestras predicciones (y muy posiblementa tengamos que simular más allá). Finalmente, como mencioné antes, a futuro necesitaremos incluir otros fenómenos para acercar más la simulación a la realidad (e.g., difusión) como así también mejorar el modo de registrar la información medida.
NW: Muchas gracias
JF: A ustedes y esperamos seguir avanzando juntos en este código.
Por Nicolás Wolovick, director del CCAD


