
Cuando supimos que obtuvimos el subsidio PFI2021 por $6.000.000, rápidamente adquirimos una placa NVIDIA A10 para probarla en un nodo de Mendieta para ver que todo estuviera ok antes de comprar 21 placas más.
Los nodos de Mendieta fase 2 son Supermicro 1027GR-TSF. Unos servidores dual Xeon 2680 v2, con lugar para poner 3 GPUs / XeonPhi en PCIe 3.0 de ese tiempo. Básicamente está pensado para placas Teslas m2070/75/90 K20m y K40m, placas NVIDIA de 5 generaciones atrás, y los XeonPhi de primera generación como por ejemplo los 31S1P, todos de enfriamento pasivo y conectores de power PCIe en el contrafrente.
Las placas NVIDIA A10 son de 2021, PCIe 4.0 y con una potencia de cálculo 20 veces mayor a las placas que estaban previstas para ese servidor. En estos casi 10 años muchas cosas pueden cambiar, así que decidimos adquirir una con fondos del CCAD y probar si nuestra intuición era correcta: que estas placas no homologadas para el 1027GR-TSF funcionan correctamente.
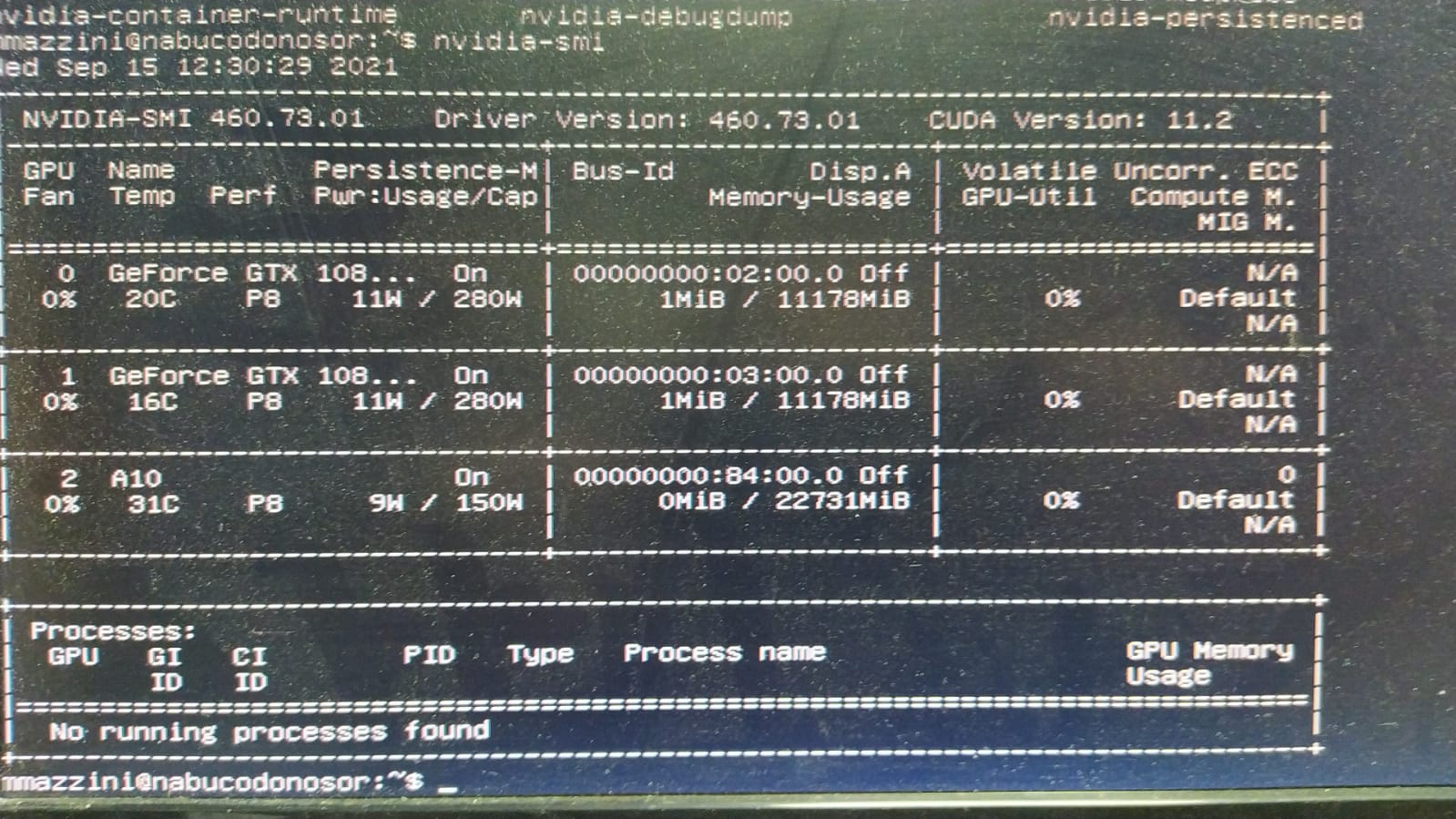
 El CPA CONICET Marcos Mazzini intervino una Nabucodonosor, le retiró una GTX 1080 Ti
El CPA CONICET Marcos Mazzini intervino una Nabucodonosor, le retiró una GTX 1080 Ti, cambió los ventiladores para que vuelvan a estar por debajo y colocó la Tesla A10 que se muestra en la foto superior. La máquina encendió y reconoció la placa correctamente.
 El investigador de CONICET Jorge Adrián Sánchez gentilmente accedió a probar entrenar sus modelos de ML en Nabu1 con la A10 y hasta ahora tiene resultados muy prometedores. En particular pudo aumentar el batch size de 32 a 128 gracias a que las A10 tienen 24 GiB contra los 11 GiB de las GTX 1080 Ti.
El investigador de CONICET Jorge Adrián Sánchez gentilmente accedió a probar entrenar sus modelos de ML en Nabu1 con la A10 y hasta ahora tiene resultados muy prometedores. En particular pudo aumentar el batch size de 32 a 128 gracias a que las A10 tienen 24 GiB contra los 11 GiB de las GTX 1080 Ti.

Vemos que la corrida está exigiendo térmicamente la A10 con una temperatura de 90C, ya que no bajamos los ventiladores a su lugar original. Gracias al DVFS de las placas NVIDIA de alta gama, se mantiene la GPU a temperatura máxima sin que resulte dañada y aun asi se obtiene un buen rendimiento de cómputo.
Otro hecho notable es la eficiencia energética. Las placas 1080 Ti consumen ~250W y las A10 ~130W, cuando resultados preliminares muestran que las A10 son al menos el doble de rápido. Esperamos cuadriplicar la eficiencia energética para la mayoría de los workloads de ML y MD que correrán en Nabucodonosor.


