
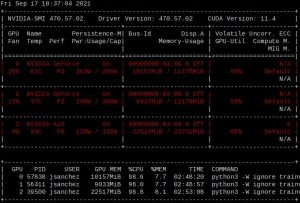
Cuando supimos que obtuvimos el subsidio PFI2021 por $6.000.000, rápidamente adquirimos una placa NVIDIA A10 para probarla en un nodo de Mendieta para ver que todo estuviera ok antes de comprar 21 placas más. Los nodos de Mendieta fase 2 son Supermicro 1027GR-TSF. Unos servidores dual Xeon 2680 v2, con lugar para poner 3 GPUs …





