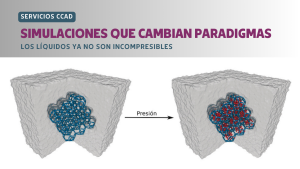
A partir de una colaboración académica se podrá acceder a cómputo interactivo en la nube y esto permite utilizar técnicas avanzadas de procesamiento de datos aplicados al desarrollo de las Ciencias Farmacéuticas. Desde hace algunos meses, el Centro de Computación de Alto Desempeño (CCAD, UNC) participa de Catalyst Project, un proyecto que busca crear …