Computar
Haswell-EP (661mm², 5.75GTr, 22nm),
GP102 (471mm², 12GTr, 16nm),
KNL (683mm², 8GTr, 14nm)

Presenter Notes
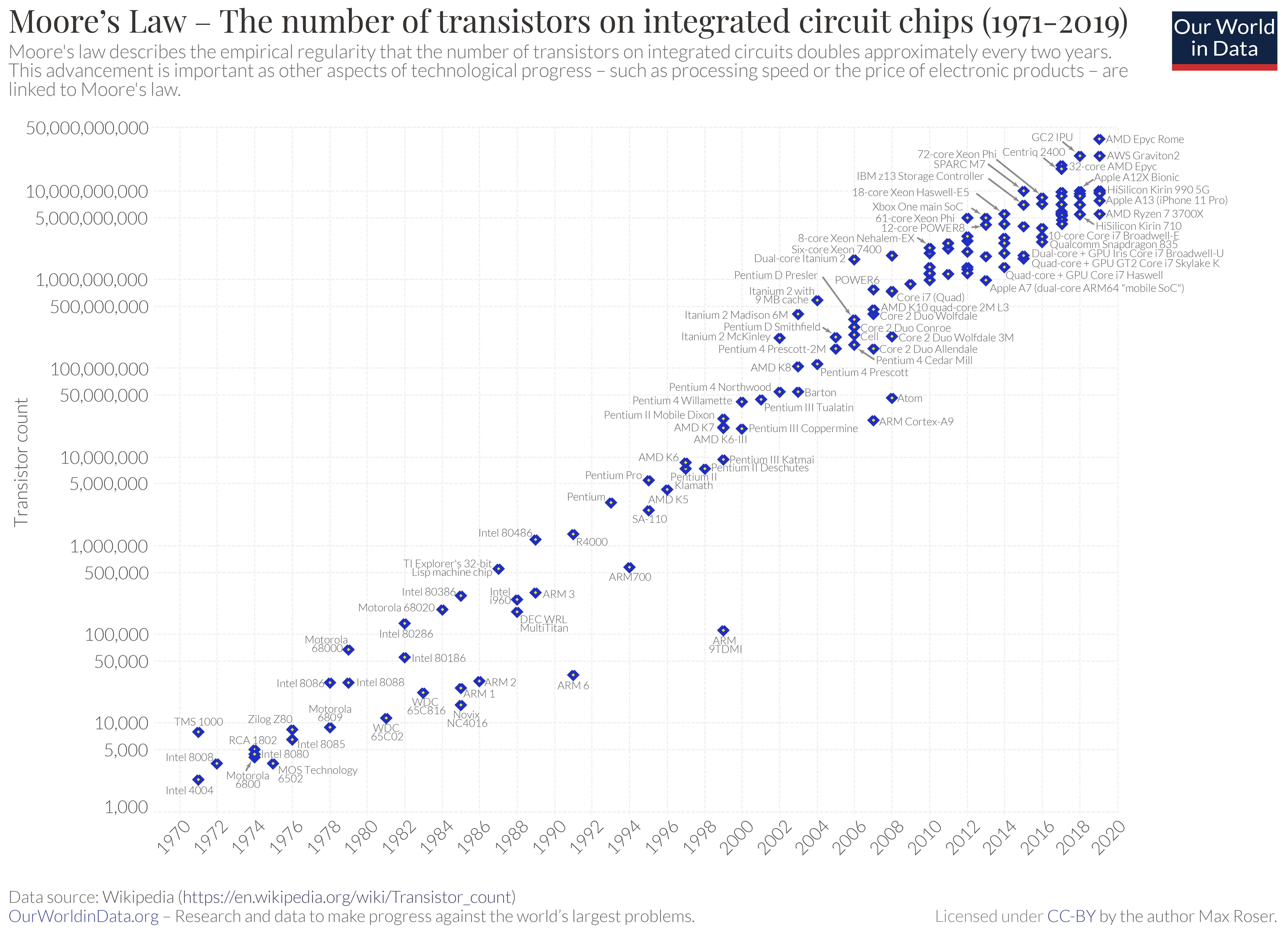
Ley de Moore, 1965

Presenter Notes

Presenter Notes
Moore todavía patea lindo
Pero los costos son los que determinan.
Intel 10 años en llegar 10nm.

Presenter Notes
Es un espacio complejo
Por ahora es un problema de costos. Creatividad y tomar riesgos: AMD Rome chiplets.


Presenter Notes
Veníamos pisteando como un campeón
Dennard Scaling

Putting it all together, in every technology generation transistor integration doubles, circuits are 40% faster, and system power consumption (with twice as many transistors) stays the same.
Shekhar Borkar, Andrew A. Chien, The Future of Microprocessors, Communications of the ACM, May 2011, Vol. 54 No. 5, Pages 67-77
Presenter Notes
Instruction Level Parallelism (ILP), aka OoO
Tomasulo Algorithm, IBM 360/91, 1968.

Scoreboarding, CDC 6600, 1964 (Seymour Cray)

Presenter Notes
... pero pasaron cosas

Presenter Notes
Todo el ILP se minó en 2001
Ley de los Rendimientos Decrecientes.

Bill Dally, The Last Classical Computer, ISAT Study, 2001.
Presenter Notes
Fin del Dennard Scaling (2005)
La corrinte de fuga se fue al tacho.

Presenter Notes
Slowing down

Hennessy, Patterson, A New Golden Age for Computer Architecture, Turing Lecture, 2018.
Presenter Notes
Solución: copypasta

- SIMD, aka DLP, aka vectorial.
- MIMD, aka TLP, aka multicore.
Presenter Notes
Pollack's Rule
argues that microprocessor performance scales roughly as the square root of its complexity, where the logic transistor count is often used as a proxy to quantify complexity.

Presenter Notes

Presenter Notes

Presenter Notes
Time Scale of Sys Lat, Brendan Gregg

Presenter Notes
Toda la verdad

(Bill Dally, Efficiency and Programmability: Enablers for ExaScale, SC13)
Presenter Notes
Speedup

Hennessy, Patterson, A New Golden Age for Computer Architecture, Turing Lecture, 2018.
Presenter Notes
Dark Silicon

¡Si prendo todos los transistores se prende fuego!
P = V²f
- Bajar el voltaje (tiene un límite computación tolerante fallas).
- Bajar la frecuencia ... o ¡AUMENTARLA!
- Especialización.
Presenter Notes
Evolución DVFS

Presenter Notes
DVFS
Dynamic Voltage and Frecuency Scaling.
Ya no se controla la frecuencia a la que opera un procesador.

Presenter Notes
DVFS RPi4, Cortex-A72

Presenter Notes

Presenter Notes
AMD Zen 2, "not-so-turbo" cores

Presenter Notes
On the dangers of Intel's frequency scaling

To keep power in check Intel introduced something called dynamic frequency scaling. It reduces the base frequency of the processor whenever AVX2 or AVX-512 instructions are used. This is not new, and has existed since Haswell introduced AVX2 three years ago.
If you do not require AVX-512 for some specific high performance tasks, I suggest you disable AVX-512 execution on your server or desktop, to avoid accidental AVX-512 throttling.
Presenter Notes
Locality is Performance

M. Själander, M. Martonosi, S. Kaxiras, Power-Efficient Computer Architectures, recent advances, 2014.
Presenter Notes
Operaciones ALU y FP son gratis

Hennessy, Patterson, Computer Architecture a Quantitative Approach, 6th ed, 2017.
Errata: FB reads FP, floating point.
Presenter Notes

Presenter Notes

Presenter Notes
Jerarquía de Memoria

La caché es una Leaky abstraction.
 que aprovecha regularidades estadísticas del acceso a la memoria por parte de los programas en ejecución.
que aprovecha regularidades estadísticas del acceso a la memoria por parte de los programas en ejecución.
Presenter Notes
Localidad

- Localidad temporal (instrucciones).
- Localidad espacial (datos).
Presenter Notes
Tipos de RAM

Presenter Notes
Memoria 2.5D
HBM1, HBM2, MCDRAM

Presenter Notes

{kind=link}
Presenter Notes
Skylake core (i.e Xeon Gold 6142)
ILP, DLP, L1i, L1d, L2

RIDL and Fallout: MDS attacks, Vrije Universiteit Amsterdam, 2019.
Presenter Notes
Skylake die
TLP, L3
